
In this experiment I have investigated a technique for giving AI behaviors a Level of Detail capability.
The idea is simple, when no one is looking we can use a more lightweight model to get the effect of the AIs activities in the world. And when someone we care about comes within range we switch to a more detailed model.
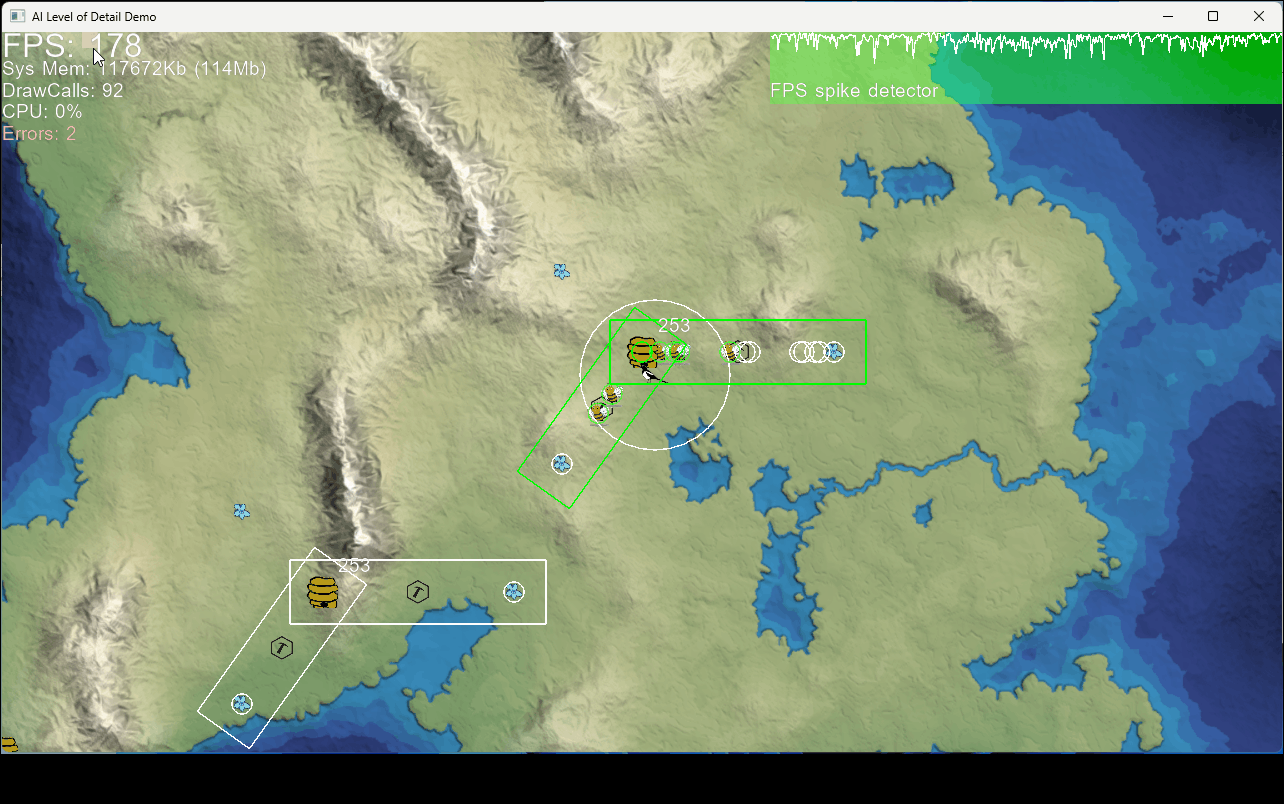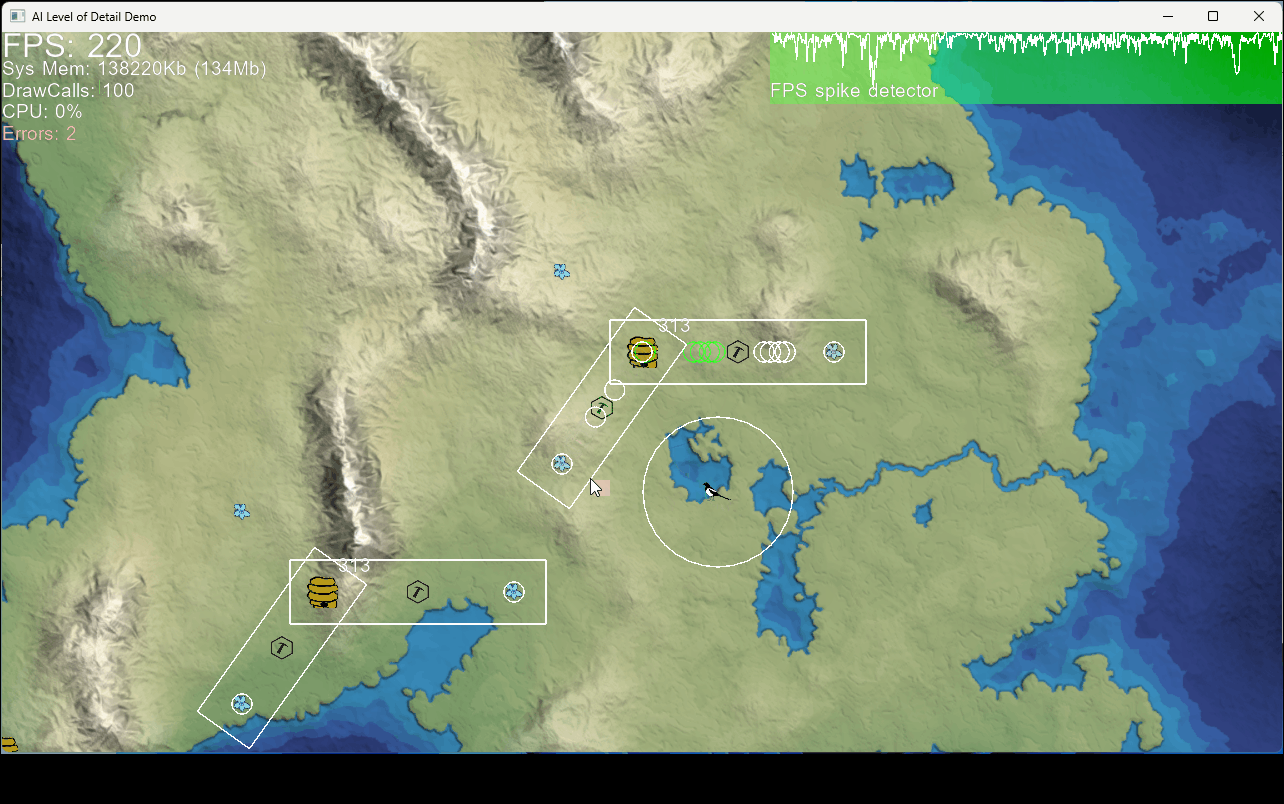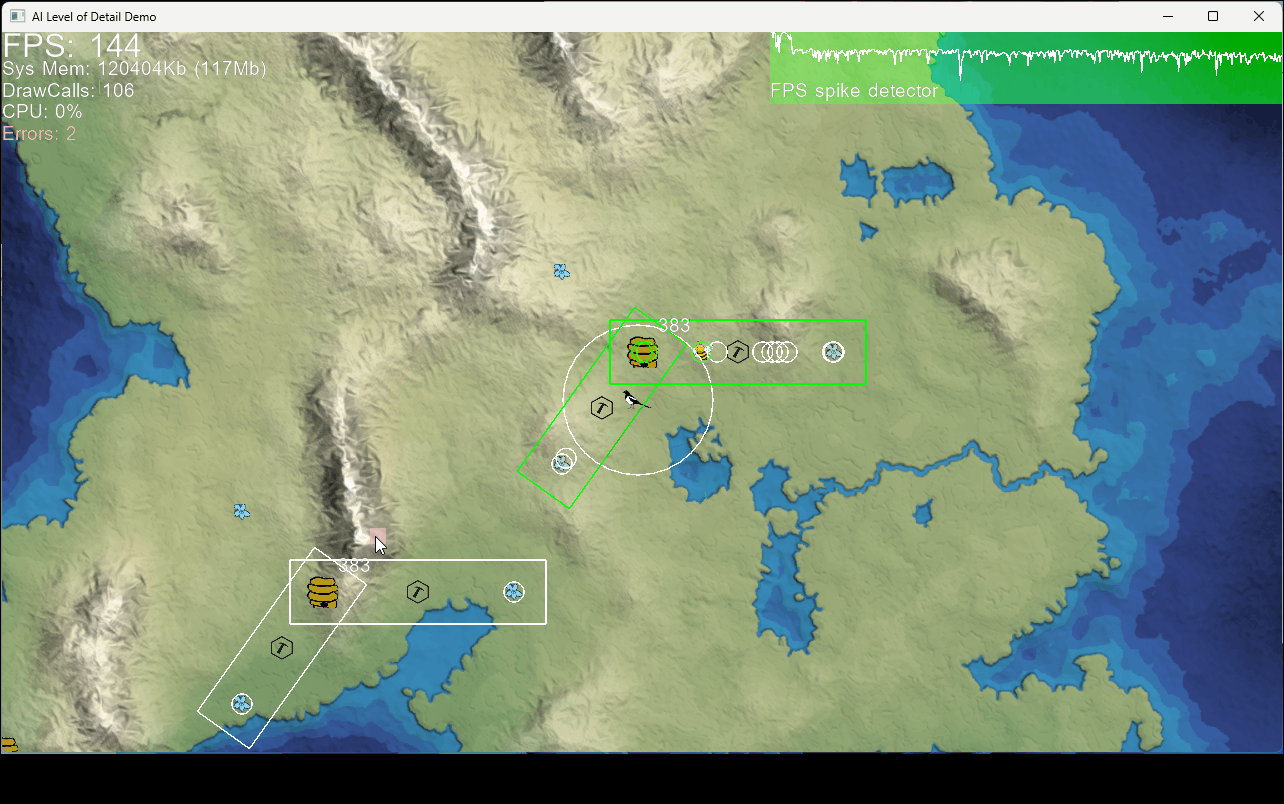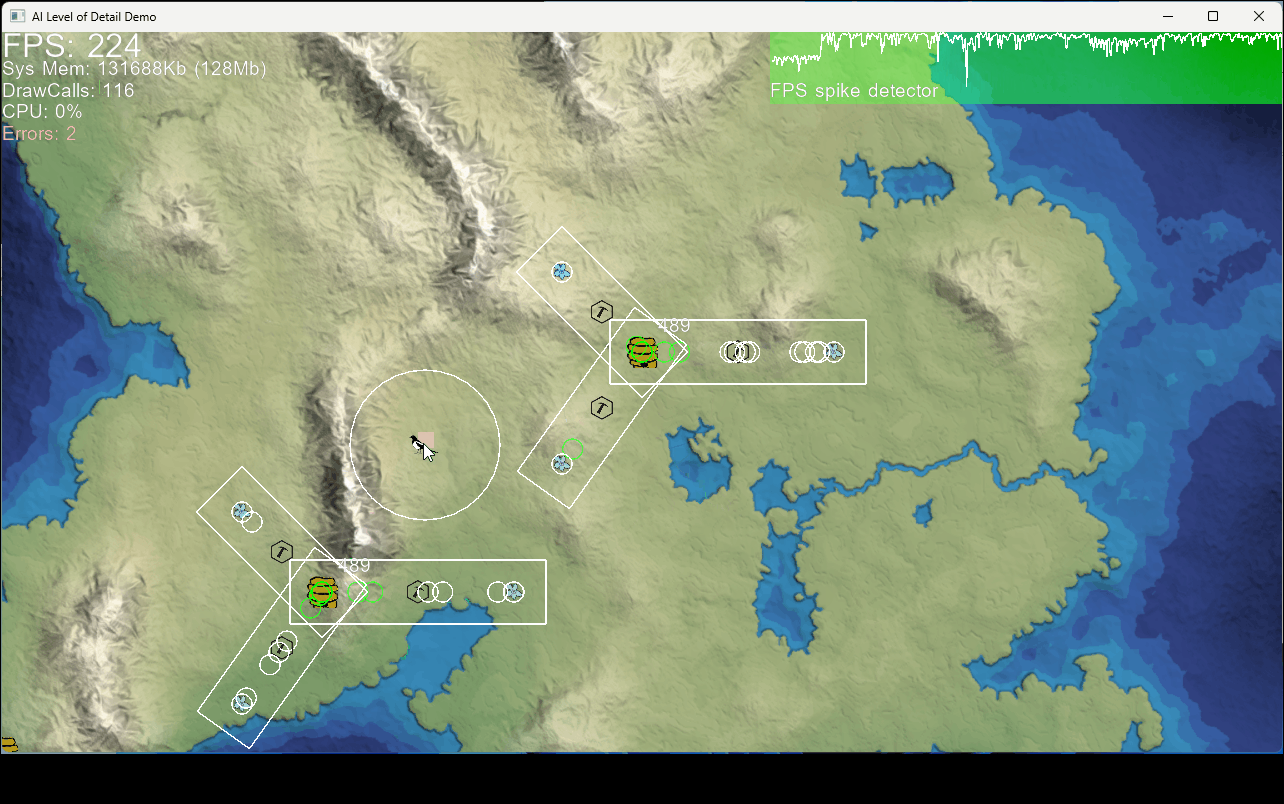
In the demo two identical beehives have workers gathering pollen to make honey. With that they can raise more bees to help out around the hive.
I’d like to draw your attention to three things in the GIF (please go the article to see the full GIF):
- The amount of collected pollen is the same in both hives whether they are observed or not. This is because care is taken that both levels of simulation meet the same constraints.
- The frame rate is notably effected when a collection area is observed. This is because the detailed model when the individual bees are shown is more expensive. In this model it is mostly just added collision detection that eat a bit of the CPU budget.
- When the ”player” moves a way from the bees it looks like they are stuck where last seen. Their positions are no longer calculated and updated at this time. But when returning to the area their current position is calculated from the completion ratio of their current behavior stage.
This demonstrate the basic idea that we can ”get away” with the more lightweight simulation for the macro level behavior, the pollen collection in this case, when there is no reason to know more details about whats going on at the micro level.
The key to this is that all state needed to recreate the detailed behavior is produced by the lightweight model, and vice versa so that switching back and forth between the two models is transparent.
Conclusions
This type of Level of Detail is mostly useful in situations where there is a lot of persistent activities/processes going on in a game. Like simulation of cities, large troop formations e.t.c..
This experiment is a bit to small to say if it is worth the extra complexity or not and I would like to scale it up in the future. However I feel that it is significant enough savings even here to motivate further experimentation at least.
I have also contemplated an alternative strategy more suitable for things like caravans or troop formations. When moving away from an observed activity we would remember that time, their current actions/state and kinematic parameters.
To compute the new position when coming back to the activity, we would calculate an area that the unit could have had time to move within and either interpolate the new position from its old one if its basically still doing the same thing. But if it has changed its action/state we could figure out a more likely position based on that action/state.
If the area of potential current position is larger than a set threshold we could chose an arbitrary position within the activity’s area of operation that is suitable for its current action/state. So for a troop formation scout units would be positioned in a flanking or forward position to the center of the activity where you would find the core of the formation, appropriately spaced and positioned according to the activity’s overall state.
I did not have time to implement this but will return to this when I get some time to spare.